You might also be interested in..
Machine Learning for recommendations
 Alex Scheel Meyer
Alex Scheel Meyer
A lot of people have asked for some more technical articles, and I definitely agree - I also tried want to understand every little detail of my favorite subjects.
Therefore, in this article I will write a kind of continuation to the Selling through Recommendations article. There are many different ways to implement it, but I will describe some good techniques that have proven their worth in several different contexts.
In general, most product proposal techniques fall into the "Collaborative Filtering" category. The fact that it is "collaborative" comes from when you want to recommend products to a specific customer, you typically do this by looking at data from a lot of other customers, and in this way you can say that the other customers' data work together collaboratively to give you product suggestions. Typically, this way you will end up with a very large number of products you can suggest, and you therefore want to choose the best ones so that it does not become too overwhelming a number of possibilities - therefore "filtering".
Mathematically, it is expressed as a (often huge) matrix that has products on one axis and customers or other products on the other.
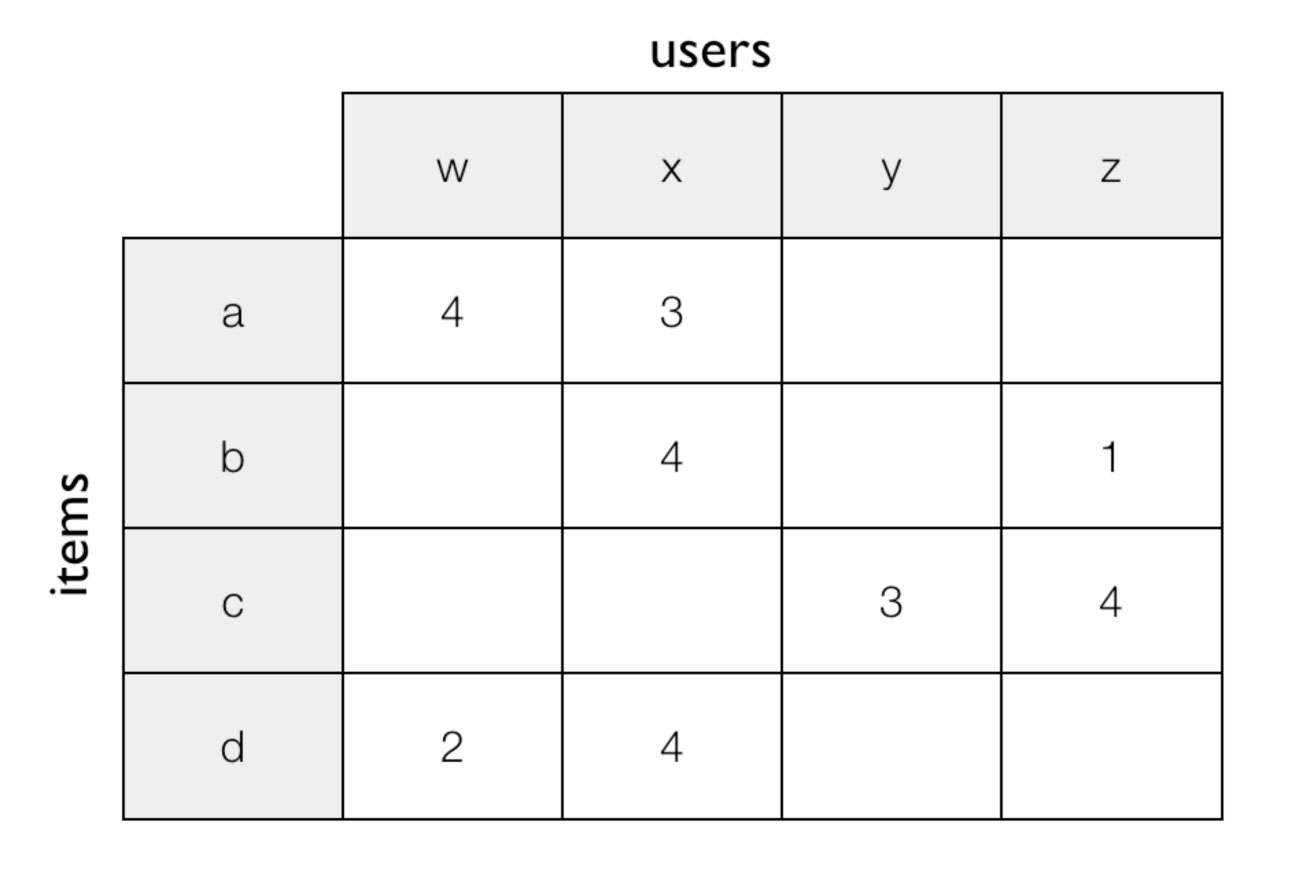
The simplest technique is to collect purchase statistics and note in the matrix every time a product is purchased with another product (you have products on both axes) and then directly use it as a score for how often product A and product B are purchased together. If a customer visits a page with product A - then either take the row or column in the matrix that belongs to A and then find the cells with the highest scores and recommend the products.
In practice, however, it makes quite boring suggestions. For example, if you are recommending a movie, there are a lot of people who have seen the movie Titanic, and so you will end up proposing Titanic to pretty much everyone who the system thinks has not already seen the movie. In most cases, people will already have seen the movie if they thought it would be of interest, so you end up "wasting" a lot of suggestions.
A really good technique for giving better suggestions is to use the technique called Pointwise Mutual Information. For this you use exactly the same matrix where you count how often 2 products are purchased together, but next to it you also have a list of how often each product is purchased overall. What you then want to achieve is to compensate for products that are just generally very popular and then only recommend products that are bought together to a surprisingly high degree.
This is where I will have to introduce some math. Mathematically, one often expresses "how often something is purchased" as what is the probability that product x is purchased and one writes it as p(x). Similarly, you can write p(x, y) to indicate how often two products are purchased together. PMI is defined as the following formula:
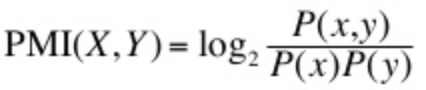
In probability theory, p(x) * p(y) is how often 2 things are expected to happen simultaneously if they are independent of each other. So basically, PMI makes it so that the number of how often 2 products are actually bought together is divided by how often you would expect them to be bought together based on pure statistics. Therefore, a ratio above 1.0 means that two products are purchased surprisingly often together and if it is below 1.0 then they are surprisingly infrequent purchased together. Traditionally, there is also a logarithmic factor that just makes the numbers less sensitive to large fluctuations due to noise in data.
With PMI, you will often get much more interesting product suggestions because it is precisely the products that are particularly closely related to people's buying patterns that are recommended. It can be a battery-powered toy and a pack of batteries, or it can be burger patties and burger buns.
PMI is good for cases where you do not know so much about a potential customer, you may only know that the customer is currently looking at a specific product. If you have additional historical data on the customer, then you can try to be more advanced. For example, if have data on a large number of customers about all the products they have purchased in the past, then you can utilize it through a simple idea: If a special group of other customers have bought many of the same products as you, then maybe you as customer in your preferences is similar to the customers who are already in that group. It will then be used to recommend products that those in the group like, but which you have not yet purchased.
In practice, a good technique for such a situation is to do matrix factorization. As with PMI, one expresses its problem as a large matrix, but instead of the matrix containing how often a product is purchased with another product - it has products on one axis, customers on the other and each cell indicates whether a customer has purchased or not (or alternatively how many stars the customer has rated the product for). Such a matrix will be very large and typically there will not be many cells that are actually filled - it is what you call a sparse matrix.
Because there are not many cells filled, it is natural to ask yourself if you can make an approximate approach that maintains buying patterns. That's what you do with matrix factorization. Instead of working on the full matrix (let's call it A), try to find 2 smaller matrices (called W and H) that when you multiply them together end up approximating A:
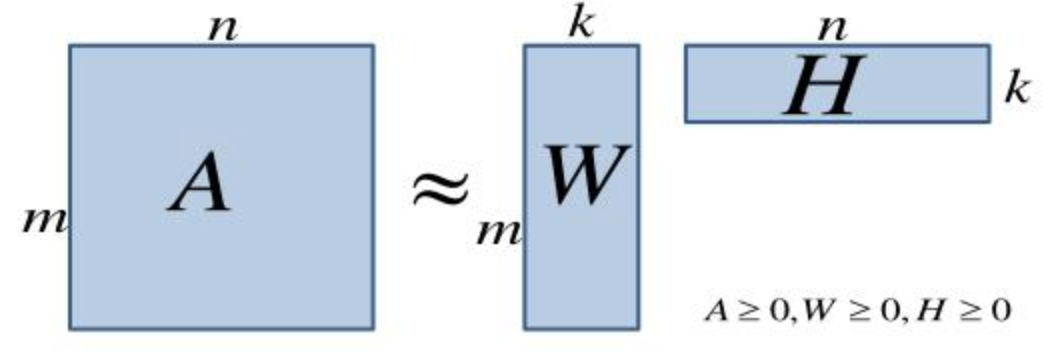
Finding these 2 matrices is a fairly standard operation as one can find programming libraries in many programming
languages to do it. If you program in Python, for example. sklearn.decomposition.NMF will do it for you. These
librariers work by you deciding how many columns and rows respectively you want in W and H and then you get the
best approximation based on these parameters.
The interesting thing is that in practice, columns and rows in W and H can be regarded as latent factors for customers and products respectively - you simply end up with a vector of numbers for each customer and for each product and when you multiply the vectors together one directly expresses how well the product fits the customer. This way you can fill in the entire matrix, even for the combinations which you do not yet have data!
At the same time, it also means that customers who have similar vectors also look similar in their product preferences - so you suddenly have the opportunity to get a number for how similar 2 customers or 2 products are to each other. You can these start using clustering techniques to visualize how one's customers divide into different segments or groups.
Sometimes you want to utilize even more data. For example it is very common to have a lot of extra data about the products. Or it may also be that customers are active on a social platform and you want to use the data (posts, likes, etc.) to describe the customers more accurately. In such cases, you need to create a more tailored machine learning model, and it will typically be a model that uses deep learning techniques. It is also in those cases that it makes special sense to hire a company like MachineReady as we already have a lot of experience in making these kinds of more advanced models.
I hope it has been exciting to read about some of the great techniques for making product suggestions. This is an area that often directly affects a company's bottom line and thus it is also a good place to start introducing machine learning in a company - you can directly measure whether you get more sales or not.