Data Analysis in Business
Data is the new oil
 Alex Scheel Meyer
Alex Scheel Meyer
We all want to make good decisions and it is hard to imagine success in business without making good decisions.
Although some people like to "shoot from the hip" when making decisions, most people want to look at things first to make sure they have the right decision-making basis. Basically, data analysis is just researching things to create a good foundation for making good decisions.
However, with the pace of data being created today, one is often motivated to analyze data simply because there may be gold grains in the data that one does not want to miss. Even without talking "Big Data", many companies will have more than enough data to analyze. Even small businesses have data on sales and cash flow, that's what accounting is. Even small businesses want to feel confident that their idea for a product can survive in the chosen market, that's what a business plan is. Even small businesses today need a sensible strategy in relation to the many potential customers found on social media.
As companies grow, the need for data analysis also increases. Machine learning techniques can help companies analyze data automatically so that it is easier and faster to find the gold grains.
A commonly used technique is t-SNE (t-distributed Stochastic Neighbor Embedding) which is a technique that can take elements with many parameters associated with it and display it as a 2-dimensional image. A bit like when a camera can take a flat view of our 3-dimensional world, only t-SNE can handle many more dimensions than 3. Below is a t-SNE visualization for product data with different classes and you can see how some products stand out nicely and are self-contained (5 and 6), while others more frequently overlap (2, 3 and 4).

Such a visualization could serve as an entry point for further analysis of the individual points, e.g. to understand why there might be more overlap than you expect.
If the same visualization was used for data about potential customers, then you might be more interested in groups that stand out a lot, considering offering those customers a product that specifically appeals to them (if it doesn't exist already).
Below is another example. This time it does not involve machine learning but is an extract and visualization of data already in the system. This project involves software development with Git version control. Each circle in the visualization is a software task that has an associated "branch" in version control. By having 3 different axes to display data, you can visualize it in several different ways and you can eg. Imagine that you would be particularly interested in finding out why some functionalities live for hundreds of days or have a lot of comments.
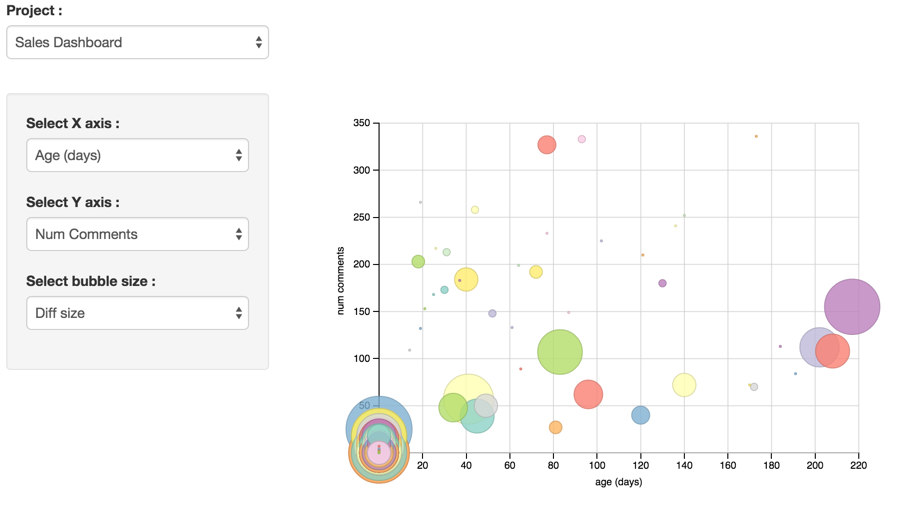
Even though machine learning is not required to make such a visualization, if you have many tasks and projects, you can as an example choose to use machine learning to estimate for each task how much the risk is that it lives for more than 50 days f. eg. This means that hopefully one can handle functionalities that prove difficult earlier in the process and possibly decide to drop it or change the requirements. In software, it is often a core task to make sure that the amount of work spent on functionality matches the value to the company.
One task that is also very popular to use machine learning for is "outlier detection", ie the detection of abnormal data.
It is used in both the insurance industry and generally when dealing with financial transactions. You use a machine learning program to simply find examples that need to be looked at by a human to investigate if fraud is involved. With the many demands placed today on the oversight of financial transactions to avoid money laundering and terrorist financing, this is almost the only way it can be done, since there are so many transactions that unless you can easily filter them, then it would be far too expensive for a human to look through them all.
Another area where outlier detection is used is in connection with quality control. Typically, you have a camera or other type of sensor that makes some measurements for each subject produced. You then use outlier detection to automatically signal when there are items that potentially do not meet the quality requirements. Again, resources can be saved by using machine learning as a filter, reducing the workload for humans.
Today, machine learning techniques for data analysis are infiltrating all parts of business processes. For some of the biggest companies, that's even the core of their business. Examples are Google and Facebook which use machine learning to "pair" between different types of content. The way it works is by training the algorithm to learn how to evaluate how well 2 (maybe very different) elements fit together. For Google and Facebook, they take information about their users and pair it with information about advertisements - that way they can optimize it so that the most relevant ads are shown. Another example is Amazon pairing products that are often purchased by the same user - here they can then use it to suggest other products you might be interested in buying, or maybe make a great deal just for you based on your prior purchases.
This change where the traditional data analysis done by people who are experts in their respective fields, is now being expanded and in some cases replaced by new techniques, that use machine learning, will continue for a long time. It will happen gradually, but it will be harder and harder to compete with companies using these techniques.
So if you are not already aware of what these techniques can do for your particular business, then it is a good idea to look into the possibilities.